最近剛好在做深度學習(deep learning)相關資料的整理
就順便把資料整理上來做一個紀錄
簡單介紹一下:從AI到deep learning影像辨識
近年來人工智慧 (Artificial Intelligence, AI) 發展非常迅速,給人們帶來許多意外驚喜。從2016年開始AI相關的技術廣泛應用於智慧控制、機器人、自動化控制、遺傳學、法學資訊、棋類遊戲、醫學領域以及語言圖像辨識領域,尤其在影像辨識、語言分析等方面,在許多的研究成果中,在單方面的能力展現已達到超越人類的水準。
但AI的發展並不是近期才開始,最早在1956年8月由被稱為人工智慧之父的約翰·麥卡錫(John McCarthy)所發起的達特矛斯夏季人工智慧研究計劃(Dartmouth Summer Research Project on Artificial Intelligence),對於AI有了初步的定義,該會議持續了一個月,進而催生後續人工智慧的發展。而AI的發展過程中,大致呈現了三個浪潮,如下圖:
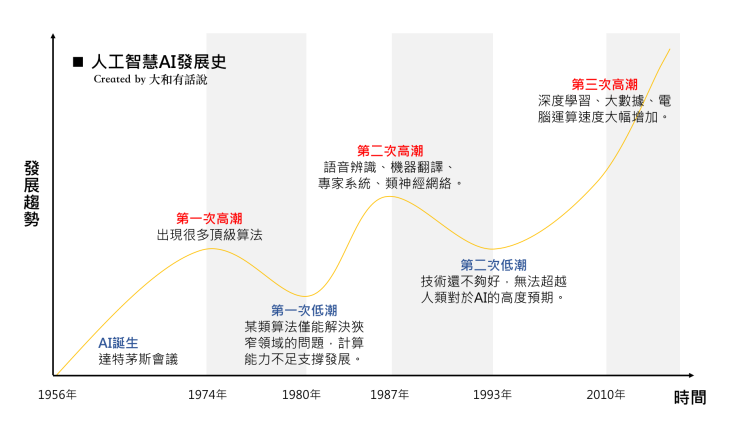
資料來源:大和有話說
在第一次的AI潮流中,由於當時的電腦運算能力有限,且發展是在網際網路之前,雖然這個階段未能提出真正有效解決實用問題的方法,但也在此奠下未來人工智慧發展的基礎。第二階段的AI高峰,出現在電腦普及的時代,這時的電腦算力逐步提升,許多以”專家經驗”作為算法邏輯的專案系統(expert system)開始發展,但由於其僅能處理特定問題或是範圍非常有限,因此熱潮很快就消退了。
而近期由於電腦性能的大幅提升,甚至是易於大量矩陣運算的Graphics Processing Unit, GPU有了快速的發展,算力的大幅提升,讓機器學習(machine learning)的想法被大量提出,其中最受矚目的深度學習(deep learning)在此佔據了非常重要的角色,由於透過模仿人腦結構和功能的數學模型-類神經網路(neural network)有了相當成熟的發展,進而能透過非常大量的數據資料來學習,而達到人類預期的辨識成果。
GPU的發展加速了深度學習(deep learning)的實用發展,比傳統CPU更適合深度學習進行開發、訓練、運算,下圖顯示採用5個CPU叢集的架構與1~3個GPU進行效能速度上的比較,在所有列出的深度學習模型上,CPU都遠遠落後於GPU的處理效能,甚至在多數模型上有極大的效能差異。
 資料來源:http://ilikesqldata.com/gpus-vs-cpus-for-deployment-of-deep-learning-models/
資料來源:http://ilikesqldata.com/gpus-vs-cpus-for-deployment-of-deep-learning-models/
深度學習(deep learning)在人工神經網路(artificial neural network)的基礎下,發展出了像是深度神經網路(deep neural networks, DNN)、卷積深度神經網路(convolutional neural networks, CNN)等多層次模型,能夠解決更複雜、更抽象的分類和識別,尤其在電腦視覺領域獲得了成功的應用,而最熱門的場域非自動駕駛莫屬了。
而其他AI的主要應用還包含了語音辨識以及自然語言處理(NLP),相關的發展早已進入一般人的日常生活,包含像apple、google、microsoft都相繼提出語音助理等服務,其成熟程度可見一班。而更進階的像是搭載了NLP的聊天機器人(chatbot),facebook與line也接連推出相關的應用服務,可達到如同真人一般的進行文字訊息的對答,也成為了大家目光的焦點。
影像辨識領域也是近年來深度學習最蓬勃發展的一塊,舉凡智慧家居、自駕車、生產瑕疵品檢測、安防監控、醫療影像等應用,都和深度學習(deep learning)影像辨識技術息息相關。雖然在一般圖片的辨識已有同等於人類的辨識率,但針對動態影像的辨識準確度卻仍比不上人類,而因此各種演算法也如雨後春筍般地推出,如下圖所示:
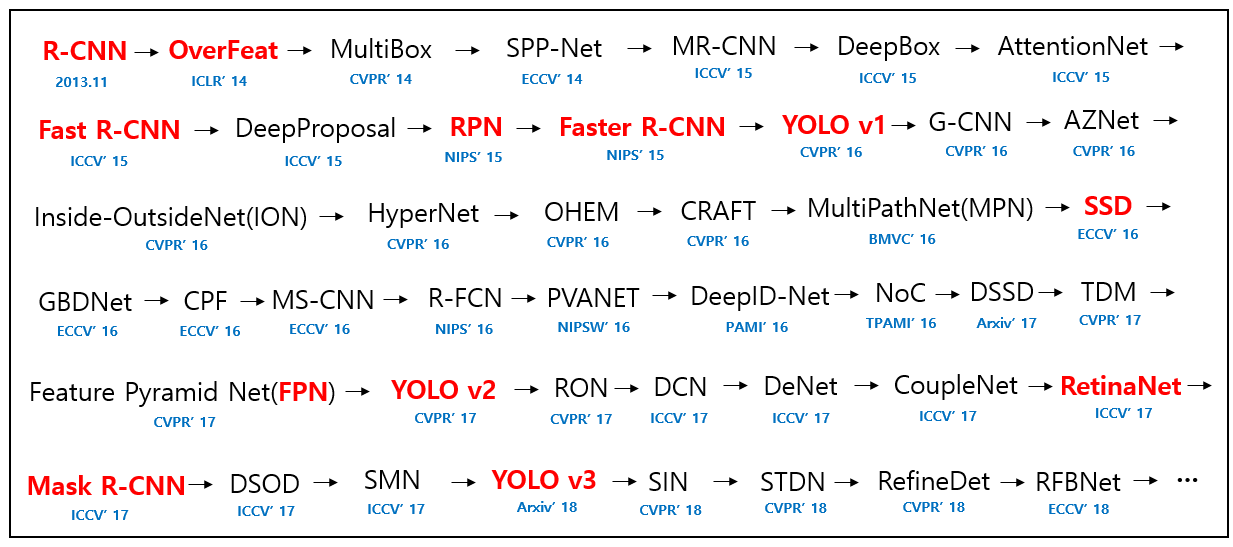
資料來源:https://pythonawesome.com/a-paper-list-of-object-detection-using-deep-learning/
而近幾年影像辨識、物件偵測(object detection)技術應用於交通領域也相當成功,最常見的應用就是將路面上的車輛偵測出來,比起過去透過移動偵測(motion detection)或是前景分離(foreground extraction)等技術的成果還要好,深度學習的技術由於透過大量影像資料的訓練,較不易受到光影變化的影響,也不易受到物體大小的限制。
許多深度學習的方法相當耗時費力,但至今已經有許多能達到即時(real time)演算的方法被提出,而其呈現的效果也相當不錯,例如像是:Faster R-CNN、SSD,YOLO等,皆已達到即時運算的程度,就算是影像中有物件重疊(overlap)的狀況,深度學習還是具有一定的偵測率,這是在過去傳統的演算法難以做到的,偵測物件的效果如下段影片所示。
物件偵測(object recognition)後加上過去的物件追蹤(object tracking)技術,就能在辨識車種、辨識行人後加入計算流量、判別移動軌跡等應用,已具有相當大的實用性。
影像辨識的發展相當早,早期從圖形識別(pattern recognition)演進而來,也就是通過電腦用數學技術方法來研究圖型的自動處理和判讀。隨著電腦技術的發展,開始研究複雜的資訊處理過程,而資訊處理過程的一個重要形式是對於環境及客觀形體的辨識。對人類來說,特別重要的是對光學資訊(通過視覺器官來獲得)的辨識,也就是圖型識別的重要發展,其也應用於聲學辨識。
圖形識別著重在抽取主要表達特徵值(features),利用這些特徵值作為分類的依據,再利用一些具備統計學的模型進行分類,進而產出我們期望的結果,例如像是採用:支持向量機(support vector machine, SVM)、隱藏馬可夫模型(hidden markov model, HMM)作為分類器。這些分類器可依據擷取出的特徵值進行訓練,訓練後產生的模型就能進行分類,整個運作流程如下圖所示:

因此早期的研究都會偏重在影像的前置處理(pre-processing)以及特徵值的擷取(features extraction),尤其是特徵值的擷取,期望能夠找到最具代表性的特徵值去進行分類器的訓練,但相關的研究很難擺脫人的主觀意識或是過去自身經驗的枷鎖。而深度學習的一大進展,就是減去了特徵值擷取(features extraction),由自身的類神經網路透過訓練階段去學習如何擷取特徵值,人工的部份僅需要專注在來源影像的標記(labeling)以及進行影像的前處理(pre-process),接著就將影像以及標記資訊進行深度學習的訓練(training),流程如下圖所示:

而圖形識別等技術在實際的應用上已經相當成功,在市場上可見到代表性的成熟技術像是文字辨識(optical character recognition, OCR)、車牌辨識(license plate recognition, LPR)、人臉辨識(face recognition)…等等,皆是過去相當受歡迎的產品。但也因為現今深度學習的快速發展,這些過去相當成熟的產品再次受到挑戰,更新更快的算法,更高的準確率,傳統的演算法可能會漸漸被深度學習的技術所取代。
在深度學習上,影像辨識相關的技術大致可分為三個類型,一種是影像分類(image classification),一種是物件辨識(object recognition),最後是加入物件分割(instance segmentation),以下進行相關的技術介紹。
(一) 影像分類(image classification)
在物件偵測的技術演進中,一開始是從影像分類(image classification) 延伸而來,從許多來源影像去進行分類,一張影像只會被判別為一種類別,簡單的流程如下圖所示:

資料來源:https://medium.com/@harsathAI/cats-and-dogs-classifier-convolutional-neural-network-with-python-and-tensorflow-9-steps-of-6259c92802f3
透過大量已分類影像作為訓練資料的來源,深度學習能夠很快速、很準確地進行分類。但這樣的功能僅適用於少數的條件,能應用的範圍不大,於是在影像分類後有了物件標記(object location)的需求,是否能在影像中把分類的物件標記出來,並明確的框選出物件的位置和大小。但這樣也僅限於一張影像裡面的一個物件,因此一張影像多個物件偵測(object detection)就成了後續發展的方向。但物件在畫面中可能並非固定的方向,因此框選的資訊也逐漸無法滿足需求,是否能更精確地描述物件的形狀,並做到實體切割(instance segmentation)的目的,成了後續發展的重點,而整個發展過程與差異可參考下圖:

資料來源:https://medium.com/zylapp/review-of-deep-learning-algorithms-for-object-detection-c1f3d437b852
(二) 物件辨識(object recognition)
物件辨識(object recognition)在深度學習上已經有相當不錯的成果,過去傳統的物件辨識技術通常需要搭配相當複雜的前置影像處理,包含影像前處理(pre-process)、前景偵測(foreground detection)、物件偵測(object detection)、物件分割(object segmentation)…等等,最後才將分割後的物件影像進行特徵值擷取(features extraction),再進一步去做物件辨識。而深度學習將大部分的動作,透過訓練的過程進行學習,流程僅需將影像作前處理(pre-process),就能將影像提供給深度學習模型(model),並產出其辨識結果,而辨識結果包含了物件偵測(object detection)的資訊,如:物件的位置、物件的大小…等;也包含了物件辨識(object recognition)的資訊,如:物件的種類、辨識分數…等。
目前主流的深度學習物件辨識模型,皆會採用MS COCO dataset做為訓練的來源影像的資料集,該資料集由微軟團隊於2014年發布,共收集了8萬多張訓練用影像,其中標記了生活上常見的80種物件,例如:貓、狗、飛機、桌子、汽車…等等,並提供了約4萬張的測試影像。而在2019年再度更新此資料集,雖然沒有新增不同的物件種類,但影像數量則增加至30萬張影像。該資料集提供了一個完全開放的內容,透過相同的資料集做為基準,各家提出的演算模型才能有客觀的比較依據。
(三) 物件切割(object segmentation)
上節所述的物件辨識(object recognition)已經能產出物件的辨識分類、辨識分數,以及物件偵測(object detection)資訊,但此資訊僅包含了像是座標位置,以及物件大小等,較為粗略的物件描述,表現出來的僅是一個框選住物件的矩形。但物件本身的形狀、物件的角度等,並不能提供比較好的描述,因此實體切割(instance segmentation) 就是在處理如何完整的切割出物件的輪廓,而不僅僅是一個位置和一個粗略的範圍,成了這塊的研究目標。
而上述提到的MS COCO dataset也包含了實體切割(instance segmentation)的資訊,最新的資料集中,包含了超過200萬個切割物件。 而基於實體切割(instance segmentation)此目的而衍生出的Mask R-CNN成了這類深度學習模型的基底,例如:mask_inception、mask_resnet是目前常見的模型。目前的技術成果,在實體切割(instance segmentation)上的效率會低於單純的物件辨識(object recognition),雖然對比過去已經有了長足的進步,許多模型已經可以達到一秒數張的處理效率,但若是以影像串流的連續性來說,還是很難達到足夠快速的運算成果,或許未來不久後,會有更快的突破性進展。
就順便把資料整理上來做一個紀錄
簡單介紹一下:從AI到deep learning影像辨識
近年來人工智慧 (Artificial Intelligence, AI) 發展非常迅速,給人們帶來許多意外驚喜。從2016年開始AI相關的技術廣泛應用於智慧控制、機器人、自動化控制、遺傳學、法學資訊、棋類遊戲、醫學領域以及語言圖像辨識領域,尤其在影像辨識、語言分析等方面,在許多的研究成果中,在單方面的能力展現已達到超越人類的水準。
但AI的發展並不是近期才開始,最早在1956年8月由被稱為人工智慧之父的約翰·麥卡錫(John McCarthy)所發起的達特矛斯夏季人工智慧研究計劃(Dartmouth Summer Research Project on Artificial Intelligence),對於AI有了初步的定義,該會議持續了一個月,進而催生後續人工智慧的發展。而AI的發展過程中,大致呈現了三個浪潮,如下圖:
資料來源:大和有話說
在第一次的AI潮流中,由於當時的電腦運算能力有限,且發展是在網際網路之前,雖然這個階段未能提出真正有效解決實用問題的方法,但也在此奠下未來人工智慧發展的基礎。第二階段的AI高峰,出現在電腦普及的時代,這時的電腦算力逐步提升,許多以”專家經驗”作為算法邏輯的專案系統(expert system)開始發展,但由於其僅能處理特定問題或是範圍非常有限,因此熱潮很快就消退了。
而近期由於電腦性能的大幅提升,甚至是易於大量矩陣運算的Graphics Processing Unit, GPU有了快速的發展,算力的大幅提升,讓機器學習(machine learning)的想法被大量提出,其中最受矚目的深度學習(deep learning)在此佔據了非常重要的角色,由於透過模仿人腦結構和功能的數學模型-類神經網路(neural network)有了相當成熟的發展,進而能透過非常大量的數據資料來學習,而達到人類預期的辨識成果。
GPU的發展加速了深度學習(deep learning)的實用發展,比傳統CPU更適合深度學習進行開發、訓練、運算,下圖顯示採用5個CPU叢集的架構與1~3個GPU進行效能速度上的比較,在所有列出的深度學習模型上,CPU都遠遠落後於GPU的處理效能,甚至在多數模型上有極大的效能差異。
深度學習(deep learning)在人工神經網路(artificial neural network)的基礎下,發展出了像是深度神經網路(deep neural networks, DNN)、卷積深度神經網路(convolutional neural networks, CNN)等多層次模型,能夠解決更複雜、更抽象的分類和識別,尤其在電腦視覺領域獲得了成功的應用,而最熱門的場域非自動駕駛莫屬了。
而其他AI的主要應用還包含了語音辨識以及自然語言處理(NLP),相關的發展早已進入一般人的日常生活,包含像apple、google、microsoft都相繼提出語音助理等服務,其成熟程度可見一班。而更進階的像是搭載了NLP的聊天機器人(chatbot),facebook與line也接連推出相關的應用服務,可達到如同真人一般的進行文字訊息的對答,也成為了大家目光的焦點。
影像辨識領域也是近年來深度學習最蓬勃發展的一塊,舉凡智慧家居、自駕車、生產瑕疵品檢測、安防監控、醫療影像等應用,都和深度學習(deep learning)影像辨識技術息息相關。雖然在一般圖片的辨識已有同等於人類的辨識率,但針對動態影像的辨識準確度卻仍比不上人類,而因此各種演算法也如雨後春筍般地推出,如下圖所示:
資料來源:https://pythonawesome.com/a-paper-list-of-object-detection-using-deep-learning/
而近幾年影像辨識、物件偵測(object detection)技術應用於交通領域也相當成功,最常見的應用就是將路面上的車輛偵測出來,比起過去透過移動偵測(motion detection)或是前景分離(foreground extraction)等技術的成果還要好,深度學習的技術由於透過大量影像資料的訓練,較不易受到光影變化的影響,也不易受到物體大小的限制。
許多深度學習的方法相當耗時費力,但至今已經有許多能達到即時(real time)演算的方法被提出,而其呈現的效果也相當不錯,例如像是:Faster R-CNN、SSD,YOLO等,皆已達到即時運算的程度,就算是影像中有物件重疊(overlap)的狀況,深度學習還是具有一定的偵測率,這是在過去傳統的演算法難以做到的,偵測物件的效果如下段影片所示。
物件偵測(object recognition)後加上過去的物件追蹤(object tracking)技術,就能在辨識車種、辨識行人後加入計算流量、判別移動軌跡等應用,已具有相當大的實用性。
影像辨識的發展相當早,早期從圖形識別(pattern recognition)演進而來,也就是通過電腦用數學技術方法來研究圖型的自動處理和判讀。隨著電腦技術的發展,開始研究複雜的資訊處理過程,而資訊處理過程的一個重要形式是對於環境及客觀形體的辨識。對人類來說,特別重要的是對光學資訊(通過視覺器官來獲得)的辨識,也就是圖型識別的重要發展,其也應用於聲學辨識。
圖形識別著重在抽取主要表達特徵值(features),利用這些特徵值作為分類的依據,再利用一些具備統計學的模型進行分類,進而產出我們期望的結果,例如像是採用:支持向量機(support vector machine, SVM)、隱藏馬可夫模型(hidden markov model, HMM)作為分類器。這些分類器可依據擷取出的特徵值進行訓練,訓練後產生的模型就能進行分類,整個運作流程如下圖所示:

因此早期的研究都會偏重在影像的前置處理(pre-processing)以及特徵值的擷取(features extraction),尤其是特徵值的擷取,期望能夠找到最具代表性的特徵值去進行分類器的訓練,但相關的研究很難擺脫人的主觀意識或是過去自身經驗的枷鎖。而深度學習的一大進展,就是減去了特徵值擷取(features extraction),由自身的類神經網路透過訓練階段去學習如何擷取特徵值,人工的部份僅需要專注在來源影像的標記(labeling)以及進行影像的前處理(pre-process),接著就將影像以及標記資訊進行深度學習的訓練(training),流程如下圖所示:

而圖形識別等技術在實際的應用上已經相當成功,在市場上可見到代表性的成熟技術像是文字辨識(optical character recognition, OCR)、車牌辨識(license plate recognition, LPR)、人臉辨識(face recognition)…等等,皆是過去相當受歡迎的產品。但也因為現今深度學習的快速發展,這些過去相當成熟的產品再次受到挑戰,更新更快的算法,更高的準確率,傳統的演算法可能會漸漸被深度學習的技術所取代。
在深度學習上,影像辨識相關的技術大致可分為三個類型,一種是影像分類(image classification),一種是物件辨識(object recognition),最後是加入物件分割(instance segmentation),以下進行相關的技術介紹。
(一) 影像分類(image classification)
在物件偵測的技術演進中,一開始是從影像分類(image classification) 延伸而來,從許多來源影像去進行分類,一張影像只會被判別為一種類別,簡單的流程如下圖所示:
資料來源:https://medium.com/@harsathAI/cats-and-dogs-classifier-convolutional-neural-network-with-python-and-tensorflow-9-steps-of-6259c92802f3
透過大量已分類影像作為訓練資料的來源,深度學習能夠很快速、很準確地進行分類。但這樣的功能僅適用於少數的條件,能應用的範圍不大,於是在影像分類後有了物件標記(object location)的需求,是否能在影像中把分類的物件標記出來,並明確的框選出物件的位置和大小。但這樣也僅限於一張影像裡面的一個物件,因此一張影像多個物件偵測(object detection)就成了後續發展的方向。但物件在畫面中可能並非固定的方向,因此框選的資訊也逐漸無法滿足需求,是否能更精確地描述物件的形狀,並做到實體切割(instance segmentation)的目的,成了後續發展的重點,而整個發展過程與差異可參考下圖:
資料來源:https://medium.com/zylapp/review-of-deep-learning-algorithms-for-object-detection-c1f3d437b852
(二) 物件辨識(object recognition)
物件辨識(object recognition)在深度學習上已經有相當不錯的成果,過去傳統的物件辨識技術通常需要搭配相當複雜的前置影像處理,包含影像前處理(pre-process)、前景偵測(foreground detection)、物件偵測(object detection)、物件分割(object segmentation)…等等,最後才將分割後的物件影像進行特徵值擷取(features extraction),再進一步去做物件辨識。而深度學習將大部分的動作,透過訓練的過程進行學習,流程僅需將影像作前處理(pre-process),就能將影像提供給深度學習模型(model),並產出其辨識結果,而辨識結果包含了物件偵測(object detection)的資訊,如:物件的位置、物件的大小…等;也包含了物件辨識(object recognition)的資訊,如:物件的種類、辨識分數…等。
目前主流的深度學習物件辨識模型,皆會採用MS COCO dataset做為訓練的來源影像的資料集,該資料集由微軟團隊於2014年發布,共收集了8萬多張訓練用影像,其中標記了生活上常見的80種物件,例如:貓、狗、飛機、桌子、汽車…等等,並提供了約4萬張的測試影像。而在2019年再度更新此資料集,雖然沒有新增不同的物件種類,但影像數量則增加至30萬張影像。該資料集提供了一個完全開放的內容,透過相同的資料集做為基準,各家提出的演算模型才能有客觀的比較依據。
(三) 物件切割(object segmentation)
上節所述的物件辨識(object recognition)已經能產出物件的辨識分類、辨識分數,以及物件偵測(object detection)資訊,但此資訊僅包含了像是座標位置,以及物件大小等,較為粗略的物件描述,表現出來的僅是一個框選住物件的矩形。但物件本身的形狀、物件的角度等,並不能提供比較好的描述,因此實體切割(instance segmentation) 就是在處理如何完整的切割出物件的輪廓,而不僅僅是一個位置和一個粗略的範圍,成了這塊的研究目標。
而上述提到的MS COCO dataset也包含了實體切割(instance segmentation)的資訊,最新的資料集中,包含了超過200萬個切割物件。 而基於實體切割(instance segmentation)此目的而衍生出的Mask R-CNN成了這類深度學習模型的基底,例如:mask_inception、mask_resnet是目前常見的模型。目前的技術成果,在實體切割(instance segmentation)上的效率會低於單純的物件辨識(object recognition),雖然對比過去已經有了長足的進步,許多模型已經可以達到一秒數張的處理效率,但若是以影像串流的連續性來說,還是很難達到足夠快速的運算成果,或許未來不久後,會有更快的突破性進展。
沒有留言:
張貼留言